opencv基础
该过程主要通过实际操作完成
素材
选取合适的高清图片,通过截屏生成新图片降低图片质量,将新的低质量图片命名为text1.png保存在python脚本的目录中
代码环境
1
2
3
| python解释器:anaconda3/python3.8
编译器:pycharm
编码:utf-8
|
代码
为了方便测试,只使用了一个脚本测试,学习笔记和部分运行结果也通过注释的方式简单加入
去除注释#即可运行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
import numpy as np
import cv2 as cv
img = cv.imread('test1.png', 1)
|
opencv进阶
注:这部分内容是有针对性的学习,暂时用不到的就没有学
性能衡量和提升技术
该部分内容,我只简单提取了cv.useOptimized()和cv.setUseOptimized()两条命令
对于部分操作的运行速度,优化会比不优化快两倍,所以我觉得有必要注意
检查是否使用优化
1
2
3
| import cv2 as cv
cv.useOptimized()
print(cv.useOptimized())
|
启用/禁用优化
1
2
3
| import cv2 as cv
cv.setUseOptimized(Ture)
cv.setUseOptimized(False)
|
其他性能优化技术
这部分内容暂时不学习,但是先做个摘记
有几种技术和编码方法可以充分利用 Python 和 Numpy 的最大性能。这里要注意的主要事情是,首先尝试以一种简单的方式实现算法。一旦它运行起来,分析它,找到瓶颈并优化它们。
1.尽量避免在Python中使用循环,尤其是双/三重循环等。它们本来就很慢。
2.由于Numpy和OpenCV已针对向量运算进行了优化,因此将算法/代码向量化到最大程度。
3.利用缓存一致性。
4.除非需要,否则切勿创建数组的副本。尝试改用视图。数组复制是一项昂贵的操作。
即使执行了所有这些操作后,如果你的代码仍然很慢,或者不可避免地需要使用大循环,请使用Cython等其他库来使其更快。
图像梯度
OpenCV提供三种类型的梯度滤波器或高通滤波器,即Sobel,Scharr和Laplacian
这是三个可以直接用的函数,暂时没搞清楚它们的原理,去了解了一下使用效果,进行实测后失败,原因未知,这里记录一下
官方使用的效果图如下:

可以看出Laplacian方法较为优秀
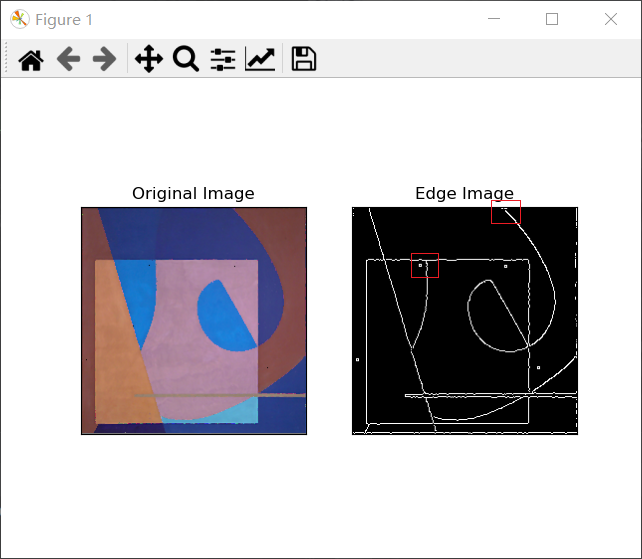
Canny边缘检测
cv.Canny()方法
这个算法,或许会对我的工作有借鉴意义,虽然思路上有很大不同,我把这种方法分类为矢量方法,而我认为我所需要做的工作属于标量方法。我个人的观点是:矢量方法更需要想象能力,标量方法更需要精密的思维;而有些东西是共通的,比如下面讲到的降噪、阈值思想
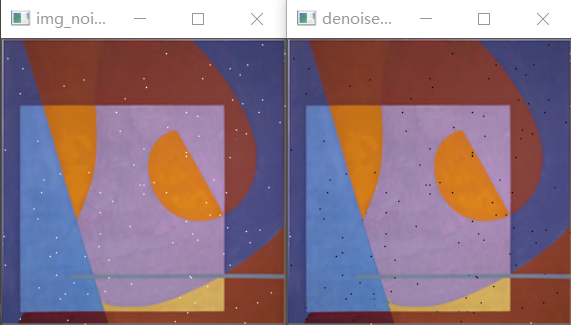
降噪
由于边缘检测容易受到图像中噪声的影响,因此第一步是使用5x5高斯滤波器消除图像中的噪声。
和上面的“图像梯度”一样,也需要降噪,由此可见,降噪在图像处理中是很重要的
查找图像的强度梯度
使用Sobel核在水平和垂直方向上对平滑的图像进行滤波,以在水平方向(Gx)和垂直方向(Gy)上获得一阶导数。渐变方向始终垂直于边缘。将其舍入为代表垂直,水平和两个对角线方向的四个角度之一。
非极大值抑制
在获得梯度大小和方向后,将对图像进行全面扫描,以去除可能不构成边缘的所有不需要的像素。为此,在每个像素处,检查像素是否是其在梯度方向上附近的局部最大值。
效果是能提取出细边
磁滞阈值
确定哪些边缘全部是真正的边缘,哪些不是。为此,我们需要两个阈值 minVal 和 maxVal。强度梯度大于 maxVal 的任何边缘必定是边缘,而小于 minVal 的那些边缘必定是非边缘,因此将其丢弃。介于这两个阈值之间的对象根据其连通性被分类为边缘或非边缘。如果将它们连接到“边缘”像素,则将它们视为边缘的一部分。否则,它们也将被丢弃。
阈值说白了,就是人为搞个界限,挑选出较明显的边缘和非边缘,用于简化计算
另外,还有些特殊情况:边缘A在 maxVal 之上,因此被视为“确定边缘”。尽管边C低于 maxVal ,但它连接到边A,因此也被视为有效边,我们得到了完整的曲线。但是边缘B尽管在 minVal 之上并且与边缘C处于同一区域,但是它没有连接到任何“确保边缘”,因此被丢弃。因此,非常重要的一点是我们必须相应地选择 minVal 和 maxVal 以获得正确的结果。
在边缘为长线的假设下,该阶段还消除了小像素噪声。因此,我们最终得到的是图像中的强边缘。
小总结
进阶部分就暂时学到这里(内容还有很多啊,但为了开始尝试一下自己的不一样的图像算法,还是先停下),不得不恭维一下opencv库,网上都说这是一个强大的库,但仅仅一个形容词“强大”,怎么能让我了解它,难不成仅仅是通过它的体积大,下载慢?
看过一些函数之后,才开始发自内心赞叹,比如单单拿出一个函数,让我封装起来,提供大部分语言的接口,供给通用场景使用,这就不是现在的我能做到的了,或许有一天我也可以吧。抽空得多看看这些函数的漂亮的源码。同时在接下来的任务中,我也期待着opencv能给我带来的新的震撼,或许会是仰止弥高,钻之弥坚。
numpy的应用
在OpenCV-Python Tutorials中也常提到numpy库,即便在根本没用到它的代码示例中,也会来一行import numpy
在实践中也发现,numpy能极大提高代码编写的效率;而查阅资料后发现,numpy对数据的索引效率远高于不使用它的情况,所以numpy也是图像处理中的一大利器。
但是由于时间原因,暂时不像学习opencv一样对numpy进行系统的学习,这里就记录一些用法
结构体数组
1
2
3
4
5
6
7
8
| import numpy as np
Mytype = np.dtype({
'names': ['value', 'noise', 'part'],
'formats': ['i', 'i', 'i']
})
array = np.zeros((m, n), dtype=Mytype)
|
numpy数组排序
由于numpy建立的数组可以很复杂,所以numpy的排序函数的参数也很多
1
2
3
4
5
6
| import numpy
numpy.sort(a, axis=-1, kind=None, order=None)
|
图像处理实战
测试1
思路
将素材图片(同附件)读入,然后通过两种划分方法的遍历比较,得出噪声值(次数),修改像素操作(容易实现)及其他特殊情况的优化先不考虑

代码
(同附件)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
|
import numpy as np
import cv2 as cv
import heapq
Pixel_type = np.dtype({
'names': ['value', 'noise', 'part'],
'formats': ['i', 'i', 'i']
})
def judge_division_degree(array):
p1 = []
p2 = []
for i in range(0, len(array)):
if array[i]['part'] == 1:
p1.append(array[i]['value'])
elif array[i]['part'] == 0:
p2.append(array[i]['value'])
if len(p1) == 0 or len(p2) == 0:
return False
expected_degree = 0
if min(p2) - max(p1) <= expected_degree:
return False
else:
return True
def division_method1(array):
p = np.sort(array, order='value')
p1 = []
for i in range(0, len(p) - 1):
p1.append(p[i + 1]['value'] - p[i]['value'])
max_index = p1.index(max(p1))
small_indexs = list(set(heapq.nsmallest(max_index + 1, p['value'])))
for m in range(0, len(small_indexs)):
for n in range(0, len(array)):
if small_indexs[m] == array[n]['value']:
array[n]['part'] = 1
return array
def division_method2(array):
p = []
for i in range(0, len(array) - 1):
p.append(array[i]['value'] - array[i + 1]['value'])
p.append(array[-1]['value'] - array[0]['value'])
min_index = p.index(min(p))
max_index = p.index(max(p))
if min_index > max_index:
for i in range(max_index, min_index + 1):
array[i]['part'] = 1
elif min_index < max_index:
for i in range(0, len(p)):
array[i]['part'] = 1
for i in range(min_index, max_index + 1):
array[i]['part'] = 0
return array
def noise_check(image_channel):
(x, y) = image_channel.shape
b = np.zeros((x, y), dtype=Pixel_type)
for i in range(0, x):
for j in range(0, y):
b[i][j] = (image_channel[i][j], 0, 0)
for i in range(1, x - 1):
for j in range(1, y - 1):
eight_neighbor1 = np.zeros(8, dtype=Pixel_type)
eight_neighbor1[0] = b[i - 1][j - 1]
eight_neighbor1[1] = b[i - 1][j]
eight_neighbor1[2] = b[i - 1][j + 1]
eight_neighbor1[3] = b[i][j + 1]
eight_neighbor1[4] = b[i + 1][j + 1]
eight_neighbor1[5] = b[i + 1][j]
eight_neighbor1[6] = b[i + 1][j - 1]
eight_neighbor1[7] = b[i][j - 1]
eight_neighbor_division1 = division_method1(eight_neighbor1)
eight_neighbor2 = np.zeros(8, dtype=Pixel_type)
eight_neighbor2[0] = b[i - 1][j - 1]
eight_neighbor2[1] = b[i - 1][j]
eight_neighbor2[2] = b[i - 1][j + 1]
eight_neighbor2[3] = b[i][j + 1]
eight_neighbor2[4] = b[i + 1][j + 1]
eight_neighbor2[5] = b[i + 1][j]
eight_neighbor2[6] = b[i + 1][j - 1]
eight_neighbor2[7] = b[i][j - 1]
eight_neighbor_division2 = division_method2(eight_neighbor2)
if judge_division_degree(eight_neighbor_division1) and \
judge_division_degree(eight_neighbor_division2):
for k in range(0, 8):
if eight_neighbor_division1[k]['part'] != eight_neighbor_division2[k]['part']:
if k == 0:
b[i - 1][j - 1]['noise'] += 1
elif k == 1:
b[i - 1][j]['noise'] += 1
elif k == 2:
b[i - 1][j + 1]['noise'] += 1
elif k == 3:
b[i][j + 1]['noise'] += 1
elif k == 4:
b[i + 1][j + 1]['noise'] += 1
elif k == 5:
b[i + 1][j]['noise'] += 1
elif k == 6:
b[i + 1][j - 1]['noise'] += 1
elif k == 7:
b[i][j - 1]['noise'] += 1
return b
img = cv.imread('test3.png', 1)
B, G, R = cv.split(img)
b_px = noise_check(B)
pf = open('output.txt', 'w')
for i1 in range(0, 302):
for j1 in range(0, 302):
print(b_px[i1][j1]['noise'], end='', file=pf)
print('', file=pf)
print("导出成功")
|
 wechat
wechat alipay
alipay