################################################################################ # END OF YOUR CODE # ################################################################################
Done extracting features for 1000 / 5000 images
Done extracting features for 2000 / 5000 images
Done extracting features for 3000 / 5000 images
Done extracting features for 4000 / 5000 images
defcompute_distances_two_loops(self, X): """ 计算X中每个测试点和self.X_train中每个训练点之间的距离。 需要使用一个嵌套循环。 输入: - X:一个形状为(num_test, D)的numpy数组,包含测试数据。 输出: - dists: 一个形状为(num_test, num_train)的numpy数组,其中dists[i, j] 是第i个测试点和第j个训练点之间的欧几里得距离。 """ num_test = X.shape[0] num_train = self.X_train.shape[0] dists = np.zeros((num_test, num_train)) for i in xrange(num_test): for j in xrange(num_train): ##################################################################### # TODO: # # 计算第i个测试点和第j个训练点之间的l2距离,并将结果存入dists[i, j]中 ##################################################################### """你的代码""" dists[i, j] = np.linalg.norm(X[i] - self.X_train[j])
##################################################################### # END OF YOUR CODE # ##################################################################### return dists
####################################################################### # END OF YOUR CODE # ####################################################################### return dists
########################################################################## # END OF YOUR CODE # ########################################################################## return dists
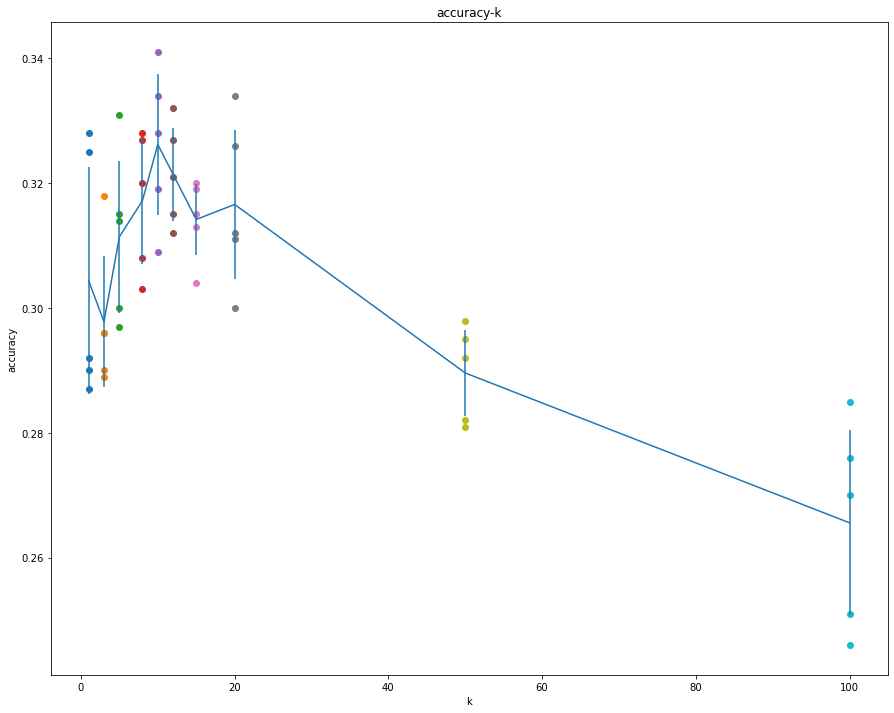
for k in k_choices: accuracies = k_to_accuracies[k] print('k = %d, average accuracy = %f' % (k, np.average(accuracies))) plt.scatter([k] * len(accuracies), accuracies)
accuracies_mean = np.array([np.mean(v) for k,v insorted(k_to_accuracies.items())]) accuracies_std = np.array([np.std(v) for k,v insorted(k_to_accuracies.items())]) plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std) plt.title('accuracy-k') plt.xlabel('k') plt.ylabel('accuracy') plt.show()
########################################################################################## # END OF YOUR CODE # ##########################################################################################
print(k_to_accuracies)
k = 1, average accuracy = 0.304400
k = 3, average accuracy = 0.297800
k = 5, average accuracy = 0.311400
k = 8, average accuracy = 0.317200
k = 10, average accuracy = 0.326200
k = 12, average accuracy = 0.321400
k = 15, average accuracy = 0.314200
k = 20, average accuracy = 0.316600
k = 50, average accuracy = 0.289600
k = 100, average accuracy = 0.265600
 wechat
wechat alipay
alipay