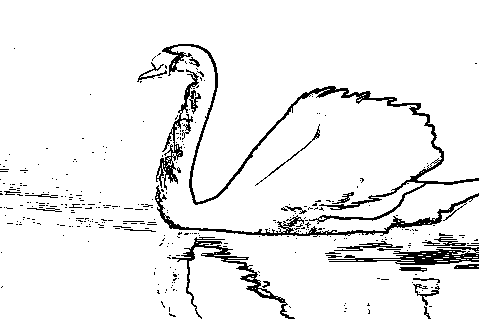
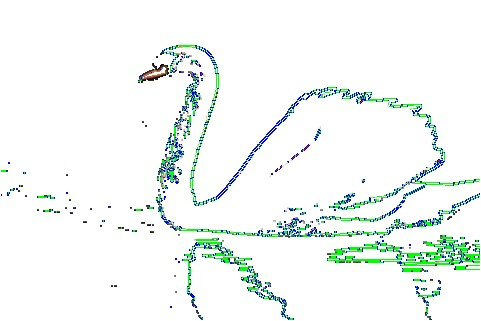
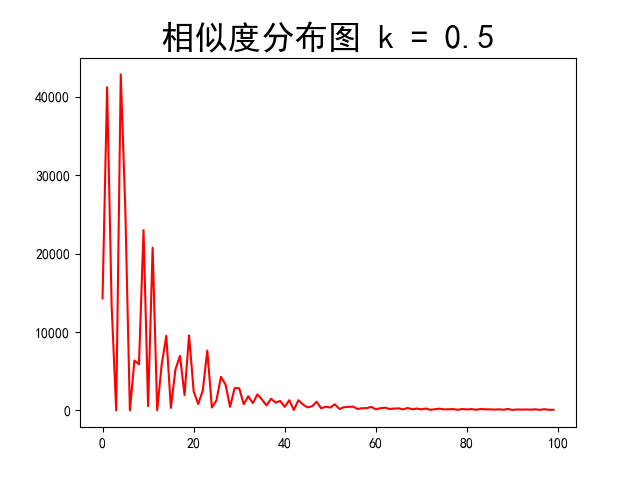
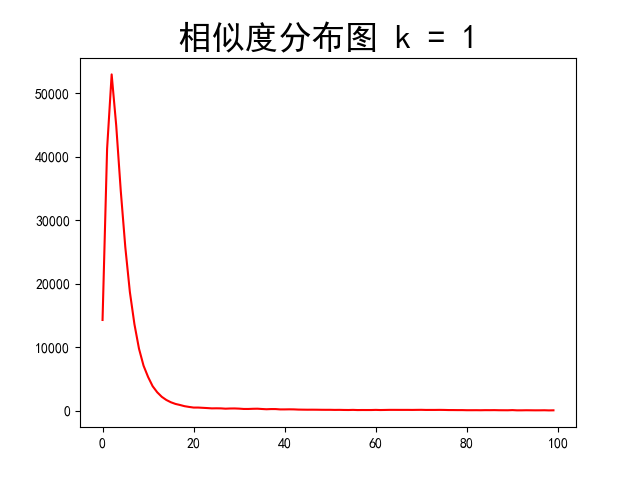
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
import cv2 as cv
import numpy as np
def get_unit_similarity(a_4, b_4, k):
a_4 = sorted(a_4)
b_4 = sorted(b_4)
result = 0
for i in range(4):
result = result + (abs(int(a_4[i]) - int(b_4[i]))) ** k
result = result ** (1/k)
return int(result)
def get_channels_similarity(channel, k):
row, col = channel.shape
result = np.zeros((row - 1, col - 1))
for i in range(row - 2):
for j in range(col - 2):
array = [channel[i][j], channel[i][j + 1], channel[i + 1][j + 1], channel[i + 1][j]]
r_array = [channel[i][j + 1], channel[i + 1][j + 1], channel[i][j + 2], channel[i + 1][j + 2]]
d_array = [channel[i + 1][j + 1], channel[i + 1][j], channel[i + 2][j + 1], channel[i + 2][j]]
r_similarity = get_unit_similarity(array, r_array, k)
d_similarity = get_unit_similarity(array, d_array, k)
result[i][j] = (r_similarity + d_similarity) / 2
return result
def get_img_similarity(img, k):
p = cv.imread(img, 1)
b, g, r = cv.split(p)
b_similarity = get_channels_similarity(b, k)
g_similarity = get_channels_similarity(g, k)
r_similarity = get_channels_similarity(r, k)
cnt = np.zeros(100)
for i in range(len(b_similarity)):
if b_similarity[i] < 100:
cnt[b_similarity[i]] += 1
for i in range(len(g_similarity)):
if g_similarity[i] < 100:
cnt[g_similarity[i]] += 1
for i in range(len(r_similarity)):
if r_similarity[i] < 100:
cnt[r_similarity[i]] += 1
def mark(channel, flag):
row, col = flag.shape
for i in range(row):
for j in range(col):
if flag[i][j] > 30:
channel[i][j] = 0
return channel
def mark_similarity(img, k):
p = cv.imread(img, 1)
b, g, r = cv.split(p)
b_similarity = get_channels_similarity(b, k)
b = mark(b, b_similarity)
g_similarity = get_channels_similarity(g, k)
g = mark(g, g_similarity)
r_similarity = get_channels_similarity(r, k)
r = mark(r, r_similarity)
p = cv.merge((b, g, r))
cv.imwrite('img_mark.png', p)
if __name__ == '__main__':
img_addr = 'img.png'
mark_similarity(img_addr, 1)
|


 wechat
wechat alipay
alipay