素材

不排序情况下的相似度分布对比
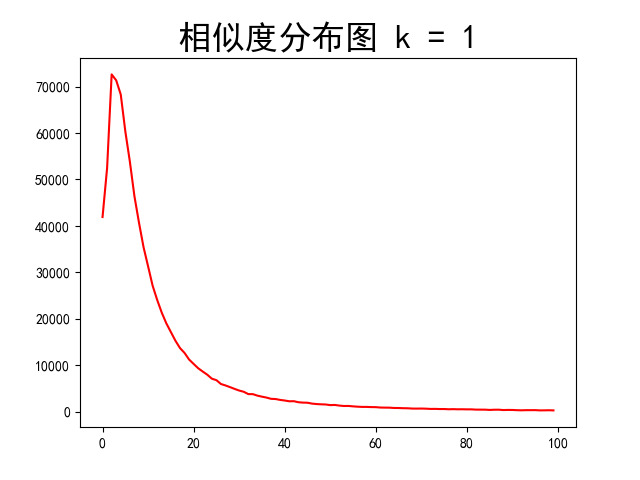
排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| 5 : 0.40026788655397105
10 : 0.626774912031553
15 : 0.7453136214204532
20 : 0.8142202385237444
25 : 0.8577027200956364
30 : 0.886459076402205
35 : 0.9067087257282348
40 : 0.9214261250471747
45 : 0.9328178480507326
50 : 0.9414958017290462
55 : 0.9484732866058905
60 : 0.9540611645211746
65 : 0.9586946420507719
70 : 0.9625351492027757
75 : 0.965824830989326
80 : 0.9686967580927699
85 : 0.9711236619306592
90 : 0.9732746077141728
95 : 0.9750601544928807
|
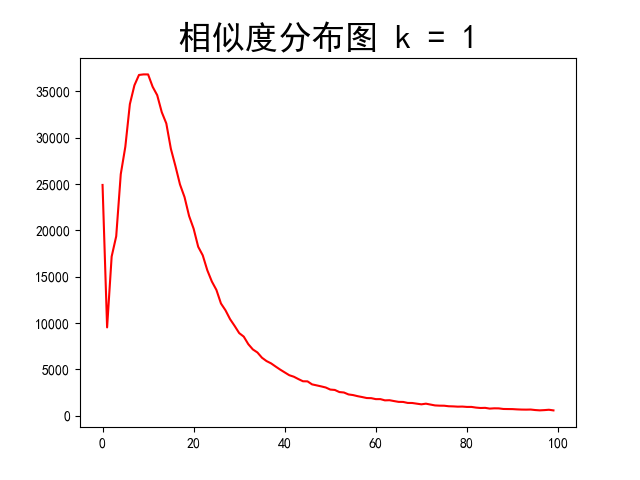
不排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| 5 : 0.1374674685811393
10 : 0.33351548746408727
15 : 0.5115215214560114
20 : 0.639375178609215
25 : 0.7258209479431854
30 : 0.7830369783792863
35 : 0.8227793011825839
40 : 0.8516174632364971
45 : 0.8733101659456853
50 : 0.8903453947727218
55 : 0.9037495391609566
60 : 0.9142632138096828
65 : 0.9231200493888565
70 : 0.9304182127952915
75 : 0.9366376310800758
80 : 0.9419419157378988
85 : 0.9465197653593017
90 : 0.9505260654925906
95 : 0.9540208070191513
|
区别
当不排序时,图像峰值向右偏移,而明显的谷值产生,由此联想到k = 0.5时的更夸张的情况
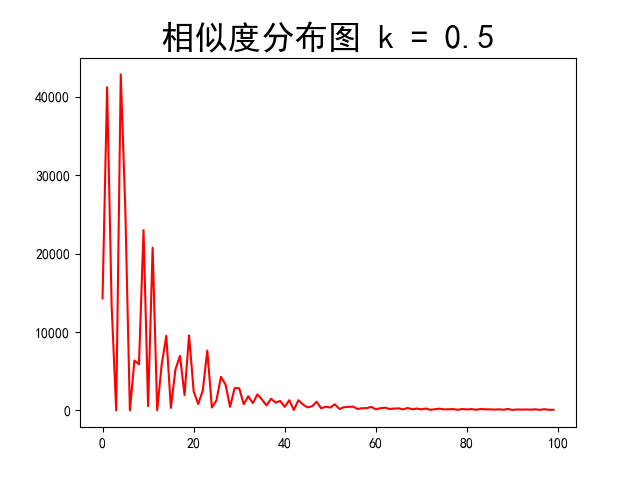
这样子的情况是合理的,但是具体的边缘检测效果,需要进行后面的测试
相似度取值及是否排序的比对
排序-平均值
参数 = 40

排序-最大值
参数 = 40

参数 = 60

不排序-平均值
参数 = 40

不排序-最大值
参数 = 40


参数 = 60

参数 = 80

不排序-第二值
参数 = 60

不排序-第三值
参数 = 60

 wechat
wechat alipay
alipay