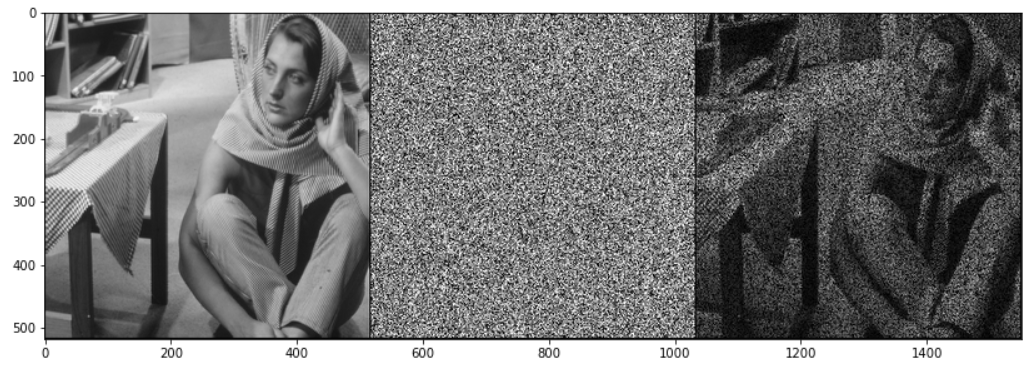
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| if 'vase.png' in img_path:
INPUT = 'meshgrid'
input_depth = 2
LR = 0.01
num_iter = 5001
param_noise = False
show_every = 50
figsize = 5
reg_noise_std = 0.03
net = skip(input_depth, img_np.shape[0],
num_channels_down = [128] * 5,
num_channels_up = [128] * 5,
num_channels_skip = [0] * 5,
upsample_mode='nearest', filter_skip_size=1, filter_size_up=3, filter_size_down=3,
need_sigmoid=True, need_bias=True, pad=pad, act_fun='LeakyReLU').type(dtype)
elif ('kate.png' in img_path) or ('peppers.png' in img_path):
INPUT = 'noise'
input_depth = 32
LR = 0.01
num_iter = 6001
param_noise = False
show_every = 50
figsize = 5
reg_noise_std = 0.03
net = skip(input_depth, img_np.shape[0],
num_channels_down = [128] * 5,
num_channels_up = [128] * 5,
num_channels_skip = [128] * 5,
filter_size_up = 3, filter_size_down = 3,
upsample_mode='nearest', filter_skip_size=1,
need_sigmoid=True, need_bias=True, pad=pad, act_fun='LeakyReLU').type(dtype)
elif 'library.png' in img_path:
INPUT = 'noise'
input_depth = 1
num_iter = 3001
show_every = 50
figsize = 8
reg_noise_std = 0.00
param_noise = True
if 'skip' in NET_TYPE:
depth = int(NET_TYPE[-1])
net = skip(input_depth, img_np.shape[0],
num_channels_down = [16, 32, 64, 128, 128, 128][:depth],
num_channels_up = [16, 32, 64, 128, 128, 128][:depth],
num_channels_skip = [0, 0, 0, 0, 0, 0][:depth],
filter_size_up = 3,filter_size_down = 5, filter_skip_size=1,
upsample_mode='nearest',
need1x1_up=False,
need_sigmoid=True, need_bias=True, pad=pad, act_fun='LeakyReLU').type(dtype)
LR = 0.01
elif NET_TYPE == 'UNET':
net = UNet(num_input_channels=input_depth, num_output_channels=3,
feature_scale=8, more_layers=1,
concat_x=False, upsample_mode='deconv',
pad='zero', norm_layer=torch.nn.InstanceNorm2d, need_sigmoid=True, need_bias=True)
LR = 0.001
param_noise = False
elif NET_TYPE == 'ResNet':
net = ResNet(input_depth, img_np.shape[0], 8, 32, need_sigmoid=True, act_fun='LeakyReLU')
LR = 0.001
param_noise = False
else:
assert False
else:
assert False
net = net.type(dtype)
net_input = get_noise(input_depth, INPUT, img_np.shape[1:]).type(dtype)
|

 wechat
wechat alipay
alipay