基于相似度对不同情况进行分类
概述12345678910graph A(取3*3的像素点) -->B(视为2*2相邻格子) B --> C(获得2*2区分度S) C -->|存在阈值D > S| D(标记为0) C -->|存在阈值D < S| E(标记为1) D --> F(对01位置进行分类) E --> F F -->|3:1| G(标为蓝色) F -->|2:2相邻| H(标为绿色) F -->|2:2对角| I(标为红色)
三种情况分开处理12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394959697989910010110210310410510610710810911011111 ...

对三种边缘现象的特征探究
概述12345678910graph A(取3*3的像素点) -->B(视为2*2相邻格子) B --> C(获得2*2区分度S) C -->|存在阈值D > S| D(标记为0) C -->|存在阈值D < S| E(标记为1) D --> F(对01位置进行分类) E --> F F -->|3:1| G(标为蓝色) F -->|2:2相邻| H(标为绿色) F -->|2:2对角| I(标为红色)
效果示例D = 20
D = 30
D = 40
代码示例1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889909192# python3.8# utf-8import cv2 as c ...

利用局部最大区分度约束边缘
利用局部最大区分度利用局部最大区分度,意图改善部分边缘提取不到的情况
代码示例123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110# utf-8# python3.8import cv2 as cvimport numpy as npdef get_unit_similarity(a_4, b_4, k): # a_4 = sorted(a_4) # b_4 = sorted(b_4) result = 0 for i in range(4): result = result + (abs(int(a_4[i]) - int(b_4[i]))) ** k r ...

基于相似度和区分度的边缘检测
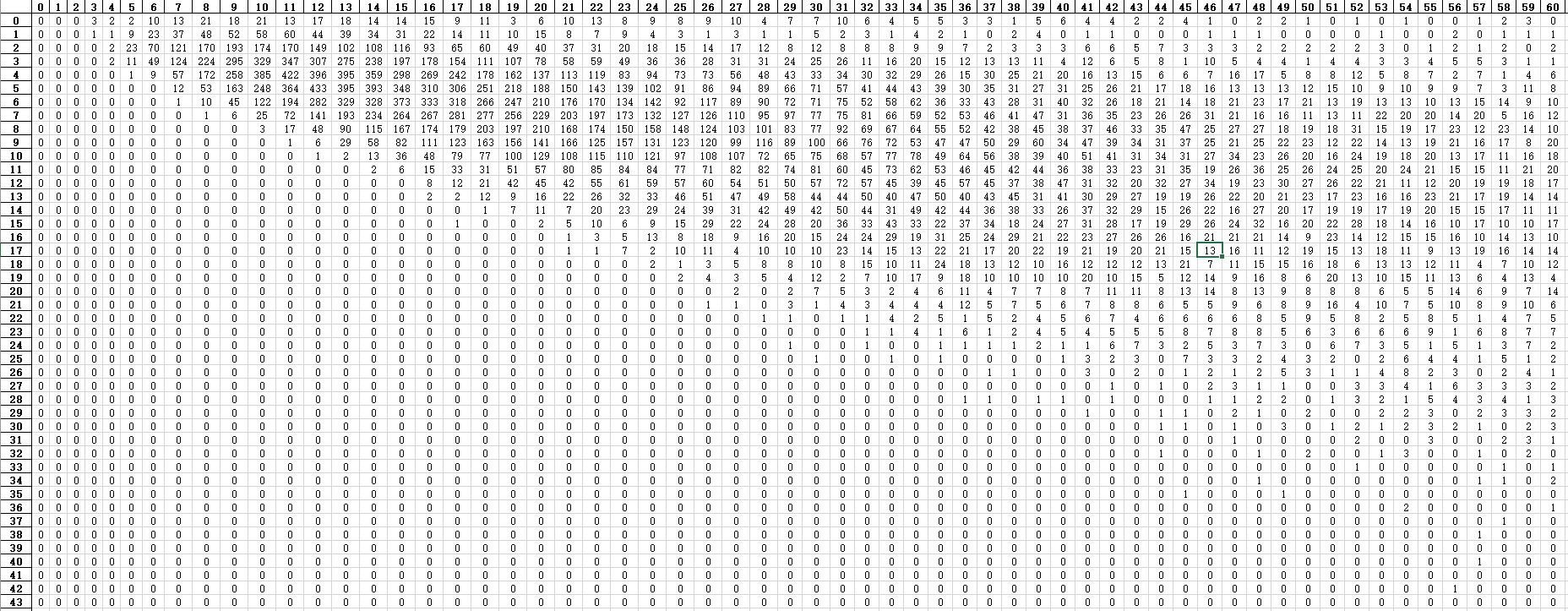
区分度分布
123456789101112131415161718195 : 0.468025173611111110 : 0.744190538194444515 : 0.850115017361111120 : 0.898198784722222325 : 0.924919704861111130 : 0.941759982638888935 : 0.952508680555555640 : 0.960366753472222245 : 0.966213107638888950 : 0.970928819444444455 : 0.974869791666666760 : 0.977977430555555565 : 0.980718315972222370 : 0.982973090277777875 : 0.984700520833333480 : 0.986343315972222285 : 0.987536892361111190 : 0.988765190972222395 : 0.9897873263888889
区分度和相似度结合相似度 > 50
相似度 & ...

基于相似度的边缘提取——对于排序与否及取值的探究
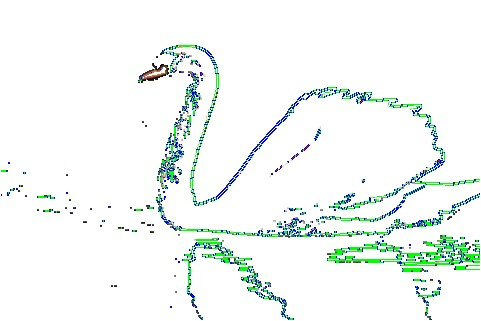
素材
不排序情况下的相似度分布对比排序
123456789101112131415161718195 : 0.4002678865539710510 : 0.62677491203155315 : 0.745313621420453220 : 0.814220238523744425 : 0.857702720095636430 : 0.88645907640220535 : 0.906708725728234840 : 0.921426125047174745 : 0.932817848050732650 : 0.941495801729046255 : 0.948473286605890560 : 0.954061164521174665 : 0.958694642050771970 : 0.962535149202775775 : 0.96582483098932680 : 0.968696758092769985 : 0.971123661930659290 : 0.973274607714172895 : 0.9750601544928807
不排序
12345678910 ...
基于相似度的边缘提取
统计相似度所占百分比素材图像
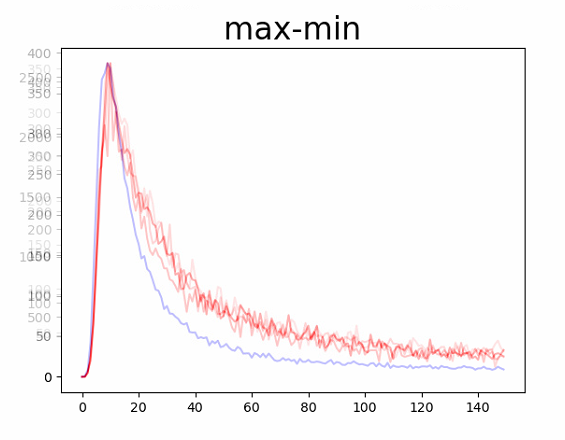
相似度分布
相似度分布占比123456789101112131415161718195 : 0.4002678865539710510 : 0.62677491203155315 : 0.745313621420453220 : 0.814220238523744425 : 0.857702720095636430 : 0.88645907640220535 : 0.906708725728234840 : 0.921426125047174745 : 0.932817848050732650 : 0.941495801729046255 : 0.948473286605890560 : 0.954061164521174665 : 0.958694642050771970 : 0.962535149202775775 : 0.96582483098932680 : 0.968696758092769985 : 0.971123661930659290 : 0.973274607714172895 : 0.9750601544928807
利用相似度提取 ...

基于相邻格间相似度的边缘检测算法
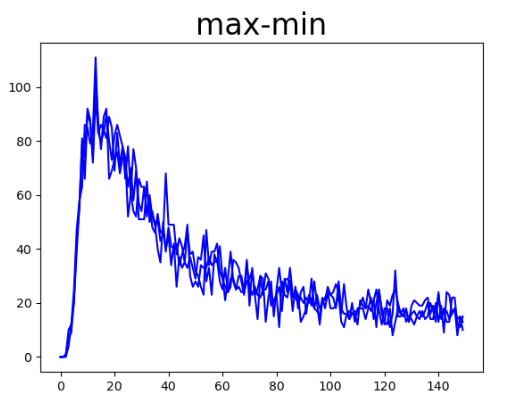
相似度分布图省略100以后的数据,得到的放大图
效果示例
代码示例1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374# utf-8# python3.8import cv2 as cvimport numpy as npdef get_unit_similarity(a_4, b_4, k): a_4 = sorted(a_4) b_4 = sorted(b_4) result = 0 for i in range(4): result = result + (abs(int(a_4[i]) - int(b_4[i]))) ** k result = result ** (1/k) return int(result)def get_channels_similarity(channel, k): r ...
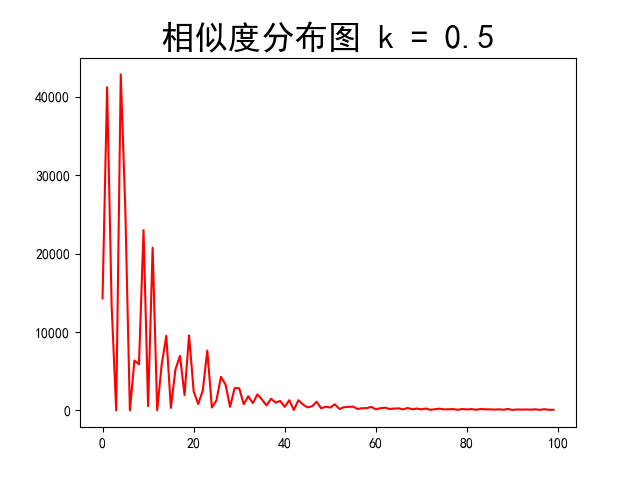
基于相邻格间相似度的分布情况
工作概述相似度探究
12345graph LR A(取2*3的像素点) -->B(视为两个相邻格子) B --> C(求取相似度S) C -->|存在阈值D > S| D[属性相同] C -->|存在阈值D < S| E[属性不同]
代码示例123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657# utf-8# python3.8import cv2 as cvimport numpy as npimport matplotlib.pyplot as pltdef get_unit_similarity(a_4, b_4, k): a_4 = sorted(a_4) b_4 = sorted(b_4) result = 0 for i in range(4): result = result + (abs(int(a_4[i]) - int ...